I am working at the
I am working at the Why Are My Bytecode Interpreters Slow? Hunting Truffles with VTune
As part of our work on the AST vs. Bytecode Interpreters paper, I briefly looked at how the native code of ahead-of-time-compiled bytecode loops looks like, but except for finding much more code than what I expected, I didn’t look too closely at what was going on.
After the paper was completed, I went on to make big plans, falling into the old trap of simply assuming that I roughly knew where the interpreters spend their time, and based on these assumptions developed grand ideas to make them faster. None of these ideas would be easy of course, requiring possibly month of work. Talking to my colleagues working on the Graal compiler, I was very kindly reminded that I should know and not guess were the execution time goes. I remember hearing that before, probably when I told my students the same thing…
So, here we are. This blog post has two goals: document how to build the various Truffle interpreters and how to use VTune for future me, and discuss a bit the findings of where Truffle bytecode interpreters spent much of their time.
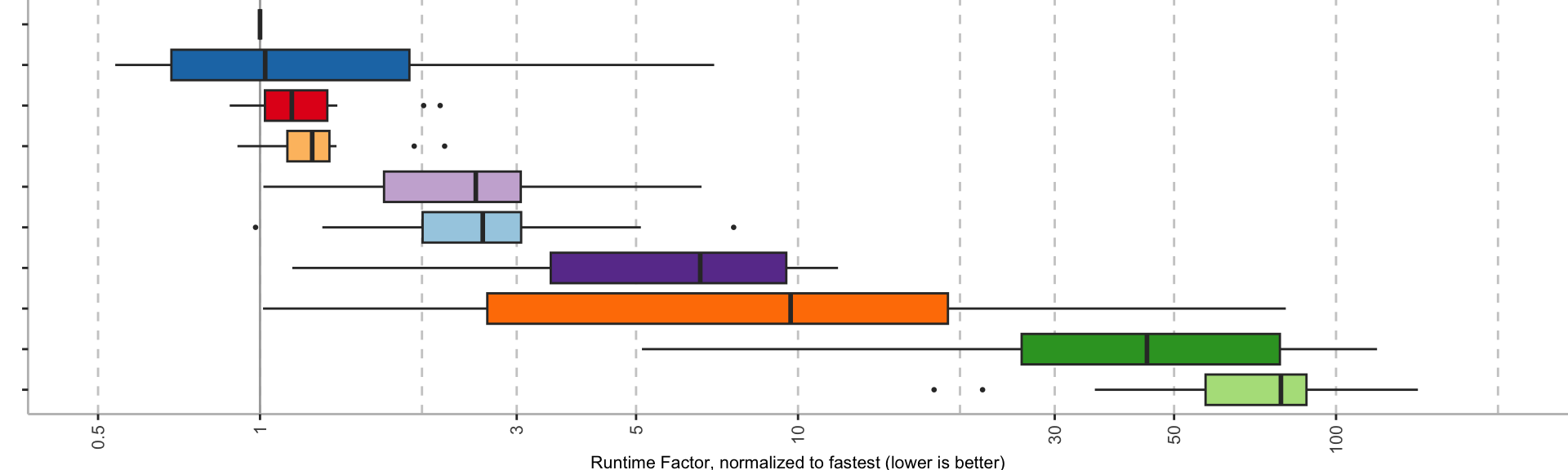
To avoid focusing on implementation-specific aspects, I’ll look at four different Truffle-based bytecode interpreters. I’ll look at my own trusty TruffleSOM, Espresso (a JVM on Truffle), GraalPy, and GraalWasm.
To keep things brief, below I’ll just give the currently working magic incantations that produce ahead-of-time-compiled binaries for the bytecode interpreters, as well as how to run them as pure interpreters using the classic Mandelbrot benchmark.
Building the Interpreters
Let’s start with TruffleSOM. The following is the command line to build all dependencies and the bytecode interpreter. It also compiles it in a way that just-in-time compilation is disabled, something which the other implementations take as a command-line flag. The result is a binary in the same folder.
TruffleSOM$ mx build-native --build-native-image-tool --build-trufflesom --no-jit --type BC
Espresso is part of the Graal repository and all necessary build settings are conveniently maintained as part of the repository. To find the folder with the binary, we can use the second command:
espresso$ mx --env native-ce build
espresso$ mx --env native-ce graalvm-home
GraalPy is in its own repository, though can also be built similarly. It also prints conveniently the path where we find the result.
graalpy$ mx python-svm
Last but not least, GraalWasm takes a little more convincing to get the same result. Here the configuration isn’t included in the repository.
wasm$ export DYNAMIC_IMPORTS=/substratevm,/sdk,/truffle,/compiler,/wasm,/tools
wasm$ export COMPONENTS=cmp,cov,dap,gvm,gwa,ins,insight,insightheap,lg,lsp,pro,sdk,sdkl,tfl,tfla,tflc,tflm
wasm$ export NATIVE_IMAGES=lib:jvmcicompiler,lib:wasmvm
wasm$ export NON_REBUILDABLE_IMAGES=lib:jvmcicompiler
wasm$ export DISABLE_INSTALLABLES=False
wasm$ mx build
wasm$ mx graalvm-home
At this point, we have our four interpreters ready for use.
Building the Benchmarks
As benchmark, I’ll use the Are We Fast Yet version of Mandelbrot. This is mostly for my own convenience. For this experiment we just need a benchmark that mostly runs inside the bytecode loop, and Mandelbrot will do a good-enough job with that.
TruffleSOM and Python take care of compilation implicitly, but for Java and Wasm, we need to produce the jar and wasm files ourselves. For Wasm, I used the C++ version of the benchmark and Emscripten to compile it.
Java$ ant jar # creates a benchmarks.jar
C++$ CXX=em++ OPT='-O3 -sSTANDALONE_WASM' build.sh
The -sSTANDALONE_WASM flag makes sure Emscripten gives us a wasm module
that works without further issues on GraalWasm.
Running the Benchmarks
Executing the Mandelbrot benchmark is now relatively straightforward. Though, I’ll skip over the full path details below. For Espresso, GraalPy, and GraalWasm, we use the command-line flags to disable just-in-time compilation as follows.
Note the executables are the ones we built above. Running for instance
java --version should show something like the following:
openjdk 21.0.2 2024-01-16
OpenJDK Runtime Environment GraalVM CE 21.0.2-dev+13.1 (build 21.0.2+13-jvmci-23.1-b33)
Espresso 64-Bit VM GraalVM CE 21.0.2-dev+13.1 (build 21-espresso-24.1.0-dev, mixed mode)
With this, running the benchmarks uses roughly the following commands:
som-native-interp-bc -cp Smalltalk Harness.som Mandelbrot 10 500
java --experimental-options --engine.Compilation=false -cp benchmarks.jar Harness Mandelbrot 10 500
graalpy --experimental-options --engine.Compilation=false ./harness.py Mandelbrot 10 500
wasm --experimental-options --engine.Compilation=false ./harness-em++-O3-sSTANDALONE_WASM Mandelbrot 10 500
Using VTune
There are various useful profilers out there, though, my colleagues specifically asked me to have a look at VTune, and I figured, it might be a convenient way to grab various hardware details from an Intel CPU.
However, I do not have direct access to an Intel workstation. So, instead of using the VTune desktop user interface or command line, I’ll actually use the VTune server on one of our benchmarking machines. This was surprisingly convenient and seems useful for rerunning previous experiments with different settings or binaries.
The machine is suitably protected, but I can’t recommend to use the following in an open environment:
vtune-server --web-port $PORT --enable-server-profiling --reset-passphrase
This prints the URL where the web interface can be accessed, and is configured so that we can run experiments directly from the interface, which helps with finding the various interesting options.
For all four interpreters, I’ll focus on what VTune calls the Hotspots profiling runs. I used the Hardware Event-Based Sampling setting with additional performance insights.
After it finished running the benchmark, VTune opens a Summary of the results with various statistics. Though, for this investigation most interesting is the Bottom-up view of where the program spent its time. For all four interpreters, the top function is the bytecode loop.
Opening the top function allows us to view the assembly, and group by Basic Block / Address. This neatly adds up the time of each instruction in a basic block, and gives us an impression of how much time we spent in each block.
The Bytecode Dispatch
VTune gives us a convenient way to identify which parts of the compiled code are executed and how much time we spent in it. What surprised me is that about 50% of all time is spent in bytecode dispatch. Not the bytecode operation itself, no, but the code executed for every single bytecode leading up to and including the dispatch.
Below is the full code of the “bytecode dispatch” for GraalWasm.
As far as I can see, all four interpreters have roughly the same native code
structure. It starts with a very long sequence of instructions that likely
read various bits out of Truffle’s VirtualFrame objects, and then proceeds
to do the actual dispatch via what the Graal compiler calls an IntegerSwitchNode in its intermediate representation,
for which the RangeTableSwitchOp strategy is used for compilation.
This encodes the bytecode dispatch by looking up the
jump target in a table, and then performing the jmp %rdx instruction at the
very end of the code below.
| Address | Assembly | CPU Time |
|---|---|---|
| Block 18 | 11.963s | |
0x1f5b229 |
xorpd %xmm0, %xmm0 |
0.306s |
0x1f5b22d |
mov $0xfffffffffffff, %rdx |
0.486s |
0x1f5b237 |
movq %rdx, 0x1f0(%rsp) |
0.080s |
0x1f5b23f |
mov $0xeae450, %rdx |
0.070s |
0x1f5b249 |
mov %r8d, %ebx |
0.346s |
0x1f5b24c |
movzxb 0x10(%r10,%rbx,1), %ebx |
0.391s |
0x1f5b252 |
movq 0x18(%rdi), %rbp |
0.050s |
0x1f5b256 |
movq %rbp, 0xd0(%rsp) |
0.030s |
0x1f5b25e |
movq 0x10(%rdi), %rbp |
0.256s |
0x1f5b262 |
movq %rbp, 0xc8(%rsp) |
0.441s |
0x1f5b26a |
lea (%r14,%rbp,1), %rsi |
0.256s |
0x1f5b26e |
movq %rsi, 0xc0(%rsp) |
0.020s |
0x1f5b276 |
lea 0xe(%r8), %esi |
0.611s |
0x1f5b27a |
lea 0xd(%r8), %ebp |
0.356s |
0x1f5b27e |
lea 0xc(%r8), %edi |
0.135s |
0x1f5b282 |
lea 0xb(%r8), %r11d |
0.055s |
0x1f5b286 |
lea 0xa(%r8), %r13d |
0.306s |
0x1f5b28a |
movl %r13d, 0x1ec(%rsp) |
0.401s |
0x1f5b292 |
lea 0x9(%r8), %r12d |
0.125s |
0x1f5b296 |
movl %r12d, 0x1e8(%rsp) |
0.065s |
0x1f5b29e |
lea 0x8(%r8), %edx |
0.326s |
0x1f5b2a2 |
lea 0x7(%r8), %ecx |
0.416s |
0x1f5b2a6 |
movl %esi, 0x1e4(%rsp) |
0.115s |
0x1f5b2ad |
lea 0x6(%r8), %esi |
0.030s |
0x1f5b2b1 |
movl %ebp, 0x1e0(%rsp) |
0.311s |
0x1f5b2b8 |
lea 0x5(%r8), %ebp |
0.356s |
0x1f5b2bc |
movl %edi, 0x1dc(%rsp) |
0.150s |
0x1f5b2c3 |
lea 0x4(%r8), %edi |
0.040s |
0x1f5b2c7 |
movl %r11d, 0x1d8(%rsp) |
0.321s |
0x1f5b2cf |
lea 0x3(%r8), %r11d |
0.416s |
0x1f5b2d3 |
movl %r11d, 0x1d4(%rsp) |
0.135s |
0x1f5b2db |
lea 0x2(%r8), %r13d |
0.065s |
0x1f5b2df |
movl %r13d, 0x1d0(%rsp) |
0.276s |
0x1f5b2e7 |
mov %r8d, %r12d |
0.426s |
0x1f5b2ea |
inc %r12d |
0.125s |
0x1f5b2ed |
movl %r12d, 0x1cc(%rsp) |
0.045s |
0x1f5b2f5 |
movl %edx, 0x1c8(%rsp) |
0.321s |
0x1f5b2fc |
mov %r9d, %edx |
0.441s |
0x1f5b2ff |
inc %edx |
0.120s |
0x1f5b301 |
movl %edx, 0x1c4(%rsp) |
0.040s |
0x1f5b308 |
lea -0x3(%r9), %edx |
0.366s |
0x1f5b30c |
movl %edx, 0x1c0(%rsp) |
0.311s |
0x1f5b313 |
lea -0x2(%r9), %edx |
0.221s |
0x1f5b317 |
movl %edx, 0x1bc(%rsp) |
0.045s |
0x1f5b31e |
lea 0xf(%r8), %edx |
0.376s |
0x1f5b322 |
mov %r9d, %r8d |
0.366s |
0x1f5b325 |
dec %r8d |
0.085s |
0x1f5b328 |
movl %r8d, 0x1b8(%rsp) |
0.045s |
0x1f5b330 |
movl %edx, 0x1b4(%rsp) |
0.371s |
0x1f5b337 |
mov %ebx, %r9d |
0.481s |
0x1f5b33a |
cmp $0xfe, %r9d |
0.035s |
0x1f5b341 |
jnbe 0x1f7c658 |
|
| Block 19 | 0.982s | |
0x1f5b347 |
lea 0xa(%rip), %rdx |
0.035s |
0x1f5b34e |
movsxdl (%rdx,%r9,4), %r9 |
0.321s |
0x1f5b352 |
add %r9, %rdx |
0.506s |
0x1f5b355 |
jmp %rdx |
0.120s |
Someone who writes bytecode interpreters directly in assembly might be mortified by this code. Though, to me this is more of an artifact of some missed optimization opportunities in the otherwise excellent Graal compiler, which hopefully can be fixed.
I won’t include the results for the other interpreters here, but to summarize, let’s count the instructions of the bytecode dispatch for each of them:
- TruffleSOM: 31 instructions in 1 basic block (after some extra optimization)
- Espresso: 79 instructions in 2 basic blocks
- GraalPy: 81 instructions in 3 basic blocks
- GraalWasm: 56 instructions in 2 basic blocks
For GraalPy it is even a little more complex. There are various other basic blocks involved and none of the bytecode handler jump back directly to the same block. Instead there seems to be some more code after each handler before they jump back to the top of the loop.
The First Micro-Optimization Opportunity
As mentioned for TruffleSOM, I did already look into one optimization opportunity. The very careful reader might have noticed the end of block 18 above.
| Address | Assembly | CPU Time |
|---|---|---|
0x1f5b33a |
cmp $0xfe, %r9d |
0.035s |
0x1f5b341 |
jnbe 0x1f7c658 |
This is a correctness check for the switch/case statement in the Java code.
It makes sure that the value we switch over is covered by the cases in the
switch. Otherwise, we’re jumping to some default block, or just back to the
top of the loop.
The implementation in Graal is a little bit too hard-coded for my taste. While it has all the logic to eliminate unreachable cases, for instance when it sees that the value we switch over is guaranteed to exclude some cases, it does handle the default case directly in the machine-specific lowering code.
Seems like one could generalize this a little more and possibly handle the default case like the other cases. The relevant Graal issue for this micro-optimization is #8425. However, when I applied this to TruffleSOM’s version of Graal, and eliminated those two instructions, it didn’t make a difference. The remaining 31 instructions still dominate the bytecode dispatch.
Conclusion
The most important take away message here is of course know, don’t assume, or more specifically measure, don’t guess.
For the problem at hand, it looks like Graal struggles with hoisting some common reads out of the bytecode loops. If there’s a way to fix this, this could give a massive speedup to all Truffle-based bytecode interpreters, perhaps enough to invalidate our AST vs. Bytecode Interpreters paper. Wouldn’t that be fun?! 🤓 🧑🏻🔬
The mentioned micro optimization would also avoid a few instructions for every switch/case in normal Java code, when it doesn’t need the default case. So, it might be relevant for more than just bytecode interpreters.
For questions, comments, or suggestions, please find me on Twitter @smarr or Mastodon.
Addendum: Dispatch Code for PySOM’s RPython-based Bytecode Interpreter
After turning my notes into this blog post yesterday, I figured today I should also look at what RPython is doing for my PySOM bytecode interpreter.
The below 13 instructions are the bytecode dispatch
for the interpreter. While it is much shorter, it also contains the
safety check cmp $0x45, %al to make sure the bytecode is within the set of
targets. Ideally, a bytecode verifier would have ensure that already,
or perhaps we setup the native code so that there are simply no unsafe jump
targets to avoid having to check every time, which at least based on VTune
seems to consume a considerable amount of the overall run time.
Also somewhat concerning is that the check is done twice.
Block 21 already has a (Correction: the second check was unrelated, and I managed to remove it by applying an optimization I had already on TruffleSOM, but not yet in PySOM.)cmp $0x45, %rax, which should make the second test
unnecessary.
So, yeah, I guess PySOM could be a bit faster on every single bytecode, which might mean PyPy could possibly also improve its interpreted performance.
| Address | Assembly | CPU Time |
|---|---|---|
| Block 20 | 0.085s | |
0xb45d8 |
cmp %r14, %rcx |
0.085s |
0xb45db |
jle 0xb6ba0 |
|
| Block 21 | 0.631s | |
0xb45e1 |
movzxb 0x10(%rdx,%r14,1), %eax |
0.311s |
0xb45e7 |
cmp $0x45, %rax |
0.321s |
0xb45eb |
jnle 0xb6c00 |
|
| Block 22 | 4.601s | |
0xb45f1 |
lea 0x69868(%rip), %rdi |
0.571s |
0xb45f8 |
movq 0x10(%rdi,%rax,8), %r15 |
0.020s |
0xb45fd |
add %r14, %r15 |
2.942s |
0xb4600 |
cmp $0x45, %al |
1.068s |
0xb4602 |
jnbe 0xb6c59 |
|
| Block 23 | 0.476s | |
0xb4608 |
movsxdl (%rbx,%rax,4), %rax |
0s |
0xb460c |
add %rbx, %rax |
0.015s |
0xb460f |
jmp %rax |
0.461s |